A Point of View
The Coming Cost Reckoning for Enterprise AI
Why inference will be governed, reduced, and charged back the way cloud spend already is, and what institutions need to build before it is.
The price is not the cost
A published rate is a starting figure. What an institution actually spends to put a model into trustworthy production is a different number, and the distance between them is the subject of this paper.
A per-unit rate presents itself as settled. In practice it is the output of a calculation the provider has already performed and the buyer never sees. Embedded in that single figure are positions on how intensively the underlying hardware will run, how many years it will stay in service, how its falling value is spread across the output it generates, and what return the provider intends to earn. Each of those positions is a variable. The rate fixes them silently and presents the result as a fact.
For an institution operating under supervision, the gap widens further. An output that cannot be explained, monitored, retained, and audited is not a cheaper output. It is one that cannot be used at all, which means the work required to make it defensible is not an optional extra on top of the rate. It is part of what the output costs. A rate that excludes it is not lower. It is incomplete.
This is the distinction the rest of the paper builds on. An organization that adopts a published rate as its planning number has not chosen a price. It has adopted, without examining them, the full set of assumptions standing behind that rate, and made them the foundation of its own budget.
Treating intelligence this way, as a managed input with its own cost structure, utilization behavior, and accountability, is the beginning of a discipline this paper calls intelligence economics©. Labor economics became necessary when labor became a managed input. Information economics followed when information did. Intelligence economics emerges now, for the same reason: machine intelligence has become a factor of production large enough to require its own economic discipline. The scale is no longer in question. Generative AI spending reached roughly $644 billion in 2025, and Gartner now puts total worldwide AI spending near $2.5 trillion for 2026, the bulk of it infrastructure rather than inference, a figure large enough that the absence of a discipline to govern it is itself the problem. What follows is a first account of that discipline, built around a method for constructing the real cost and a model for governing it.

We have seen this before
Public cloud went through the same arc: capability first, cost crisis second, governance third. AI inference is entering the second phase now.
The trajectory is familiar because the industry lived it with public cloud. Adoption began as a capability question. Could the workload run there at all, and what did it unlock. Cost was a secondary concern, tolerated as the price of speed and elasticity. Then the invoices arrived, and they were large, opaque, and difficult to attribute. Nobody could say with confidence which team, product, or decision had generated which portion of the bill. The spend was real, but it was unowned.
That cost crisis produced a discipline. It went by the name FinOps, but the substance was older than the label: make the spend visible, make it attributable, make it someone's responsibility. Tagging, cost allocation, showback, chargeback, unit economics, reserved-instance planning. None of it was glamorous, and all of it became table stakes for running cloud at scale in a serious institution.
Inference now sits where cloud sat at the start of its cost crisis, and the early signals are already visible. The FinOps Foundation's annual survey found the share of organizations managing AI spend rising from under a third to roughly two-thirds in a single year, and to nearly universal the year after, the fastest expansion of a cost-management concern the practice has recorded. Inference spending has crossed training spending for the first time, with industry forecasts putting a majority of AI infrastructure spend on inference rather than training, the marker of a technology moving from pilots into production at scale. Yet attribution lags badly: few institutions can answer the basic question of which business activity consumed which portion of inference cost, and whether it was worth it. The institutions that answered that question early for cloud spent less and governed better than those that waited. The same opportunity is open now, and for the same reason: the discipline can be built before the crisis forces it.
The parallel instructs, but it is not exact, and the differences are where a borrowed method fails. Inference cost is far more volatile than compute cost: it can swing by an order of magnitude week to week, driven by model choice, prompt design, and output length in ways raw infrastructure never was. Model selection is a cost lever with no clean cloud precedent, since the same task routed to a smaller model can cost a fraction of the larger one, trading against quality in a way provisioning decisions never did. A single poorly formed prompt can cost many times an optimized one, which means engineering choices that look purely technical are now financial ones. And the work of making an output defensible attaches to the output and the decision, not to a machine, so it resists the infrastructure-style allocation that cloud practice relies on. A method lifted whole from cloud cost management will miss all of this. One informed by it and adjusted for these differences will not.
There is a deeper difference, and it cuts in the institution's favor rather than against the thesis. Cloud governed infrastructure: machines, storage, network, things one step removed from any business decision. Inference governs the output itself, which feeds directly into decisions that carry regulatory and reputational consequence. The object under management is no longer a resource but a judgment. That raises the stakes of attribution rather than lowering them, because a misallocated compute cost is an accounting error while a misgoverned inference is a decision the institution may have to defend. Inference, in other words, may demand more governance than cloud ever did, not less, precisely because what it produces is closer to the business.
A skeptic will object that unlike cloud, where unit costs fell gradually, model costs are collapsing fast enough to make the whole concern moot. Why build a discipline around a cost that is dropping. The objection has the mechanism backwards. Inference unit cost has fallen sharply, Stanford's AI Index tracked the price of a representative inference task falling from around twenty dollars to roughly seven cents per million tokens over about two years, and over the same period total enterprise AI spend rose anyway, because usage expanded faster than price fell. Cheaper inference does not shrink the bill; it removes the friction that was holding usage down, and consumption floods into the space the price drop opened. More important, the governance load does not fall on the same curve as the model. Controls, audit, explainability, and oversight are tied to risk and regulation, not to the price of compute, so as the model gets cheaper the control environment becomes a larger share of total cost, not a smaller one. Falling model prices make governance more of the problem, not less.
June 2026 added a complication the falling-price assumption cannot absorb. The most capable generally available model launched at double the per-token rate of the flagship it replaced, and within a day a public benchmark measuring cost per finished task showed that model, at its lowest effort setting, coming within a point of the best score any prior model in its family had posted, at roughly half the cost per task and under a third of the tokens. The quoted price rose while the cost of comparable finished work fell, in the same week. A planning model anchored to the per-token rate could not have anticipated either movement, because both were produced by consumption behavior the rate does not describe.
the discipline can be built before the crisis forces it

Visibility, reduction, chargeback
The practice follows the same sequence the cloud reckoning did, because each phase depends on the one before it.
A cost-governance practice for inference is not a single intervention. It is a sequence, and the order is not arbitrary. Each phase creates the conditions the next one requires.
Phase one: visibility. Nothing can be reduced or attributed that cannot first be seen. The opening work of any engagement is instrumentation: establishing what is being spent, on which models, by which workloads, at what utilization, and under which capacity model. This is the inference equivalent of cloud tagging and cost allocation, and most institutions do not have it. The deliverable is a clear, current picture of inference cost decomposed into its real components, including the governance load the vendor invoice never shows.
Phase two: reduction. Once cost is visible, the levers reveal themselves, and they map directly to the structure of the spend. Is a workload on the capacity model that fits its utilization, or is it paying consumption rates for steady, predictable demand. Is it routed to a more capable and more expensive model than the task requires, a lever now automated by hyperscaler and commercial routing platforms, which lowers direct inference cost without producing the visibility, attribution, or control evidence the surrounding phases depend on. Is reserved capacity sitting idle, converting a discount into a loss. Is governance load being counted at all. Reduction produces the near-term return that justifies the work and earns the standing to attempt the harder phase that follows.
Phase three: chargeback. The durable change is attribution. Chargeback assigns inference cost to the business units that consume it, and that assignment changes behavior: a function that pays for its own inference uses it differently than one drawing on a central pool it does not see. This is the phase that converts cost management into cost governance. It is also the hardest, and the difficulty is not technical. Chargeback is a change-management problem wearing a cost-model costume. The allocation method must be defensible, the sponsorship must be executive, and the organization must accept the model as fair. In cloud, this is precisely where most efforts stalled, not for want of a spreadsheet, but for want of the will to make consumption visible to those who would rather it stayed hidden.
Chargeback is a change-management problem wearing a cost-model costume.

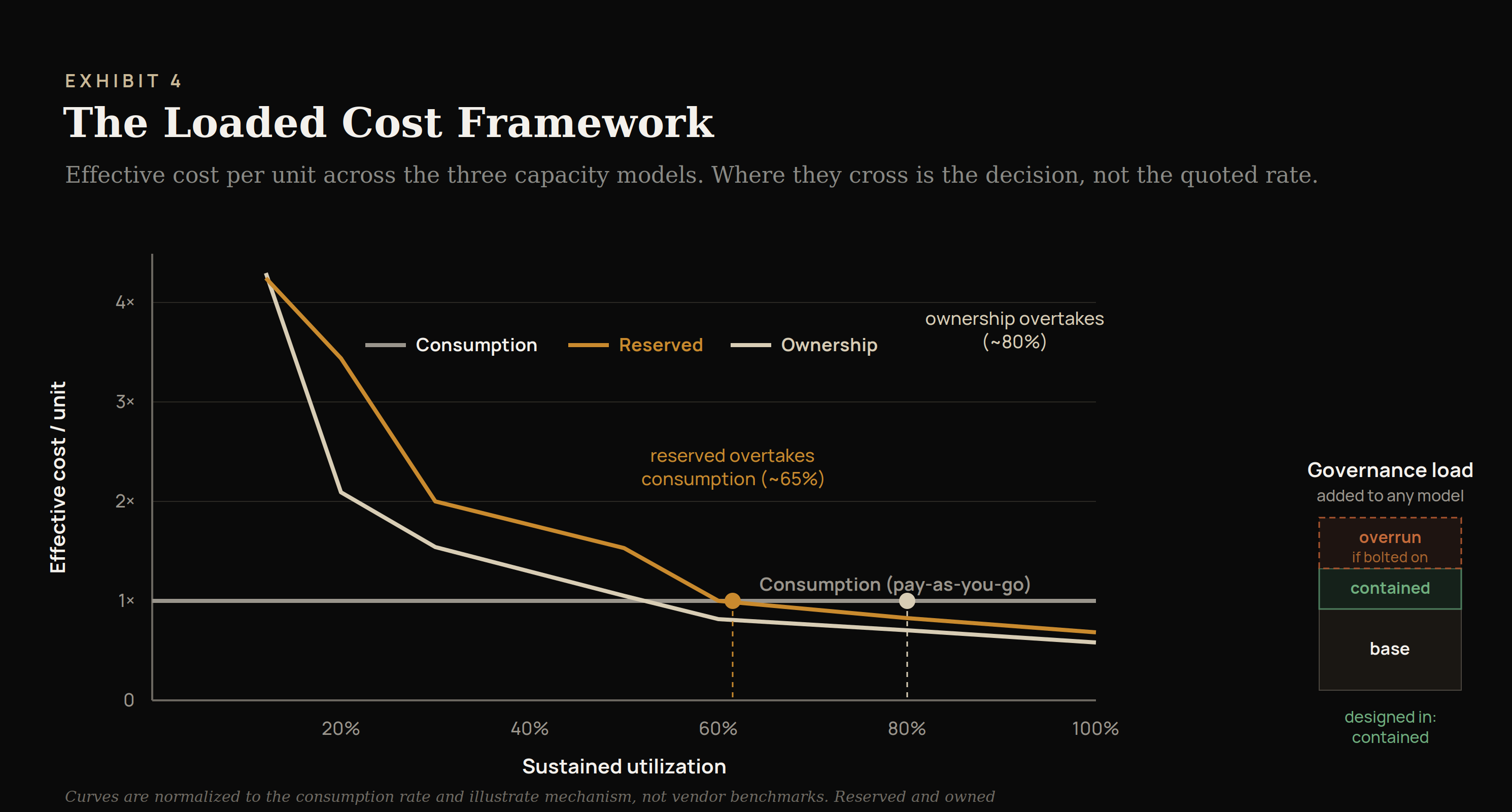
The Loaded Cost Framework
To manage the economics of intelligence consistently, an institution needs a consistent way to construct cost. The Loaded Cost Framework does this in four layers.
The published rate is a single number standing in for a calculation the institution should be doing itself. The Loaded Cost Framework is that calculation, built up the same way every time so that figures from different teams rest on the same basis and can be compared. It operates at a deliberately high level here; the detailed mechanics are established in engagement. The structure, four layers, is stable across them.
Put simply: the direct cost is the figure everyone sees, the capacity-model adjustment determines what the effective rate actually becomes at real utilization, the governance load is the part the invoice leaves out and the part whose size the institution sets by when it acts, and the allocation basis decides whose budget ultimately carries the total. A practice that keeps all four in view produces a number that withstands examination. One that collapses them back into a single quoted rate produces a number that does not.
Beneath the allocation basis sits a prior question the framework must now ask explicitly: what unit the cost is denominated in. The structures most institutions inherited assume the unit of consumption is an interaction, a seat, a query, a call. The current model generation undermines that assumption. A model that works autonomously across an extended run returns a finished piece of work rather than a stream of answers, and the deliverable becomes the unit the economics organize around. Public benchmarks have already adopted it, reporting cost per finished task alongside quality. Suppliers are moving the same direction, granting consumption-based plans full access to new capability while seat-based plans wait. When the unit of value is a finished task, per-seat and per-query allocation misprice in both directions at once: exploratory use is overcharged relative to the value it creates, while a single long-running task that consumed what a thousand interactions would is buried inside an averaged rate no one examines. The allocation basis decides whose budget carries the cost. The unit of account decides what is being counted, and it is moving from the interaction to the deliverable.
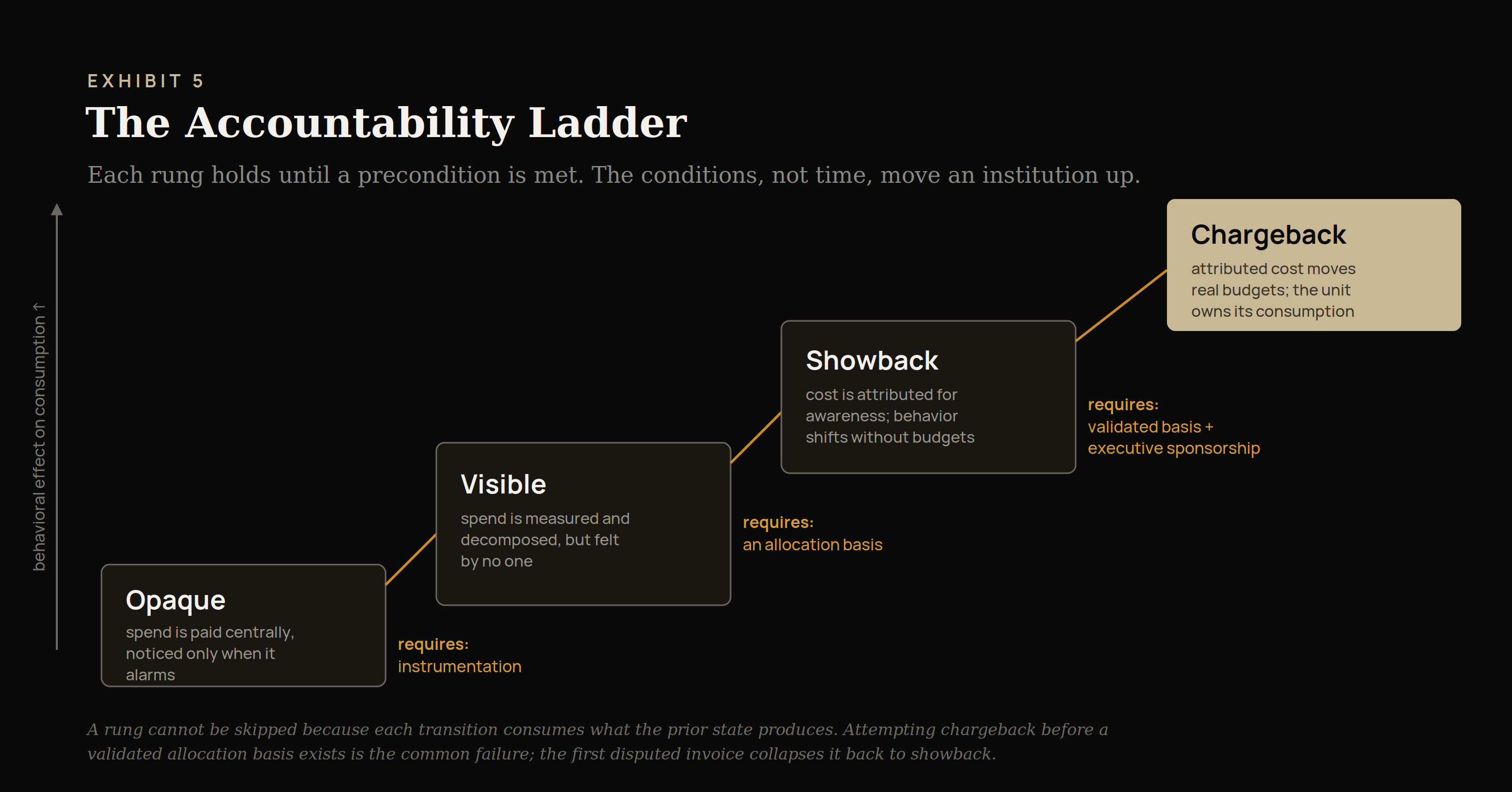
The Accountability Ladder
Institutions do not arrive at chargeback in one step. They climb to it, and the rungs are defined by how much of the cost anyone is actually accountable for.
The economics of intelligence is a capability an institution grows into, not a switch it throws. The Accountability Ladder names the climb. It serves two purposes: it locates where an institution stands today, and it sequences where it goes next without skipping the steps that make each stage hold. What changes from rung to rung is accountability, from a cost no one owns to a cost the consuming unit owns outright.
The ladder is also a guard against a common failure: attempting chargeback before showback has proven the allocation model and built organizational trust in it. The institutions that skip the middle rungs tend to fall back down them when the first allocation dispute turns political. Climbing in order is slower and holds.
What to build before the reckoning
The argument reduces to a few commitments an institution can begin now, ahead of the pressure that will eventually compel them.
- Treat the published rate as a figure to interrogate, not a number to budget. Separate out the assumptions behind it before it anchors any decision.
- Instrument inference spend for visibility before trying to reduce or attribute it. The order is a dependency, not a preference.
- Adopt one reference cost model across the institution, governance load included, so figures from different teams can be compared and defended on the same basis.
- Design governance in rather than bolting it on, since that single choice determines whether the compliance layer stays a contained increment or becomes an overrun.
- Approach chargeback through showback, and treat it as the change in incentives it actually is rather than the accounting exercise it resembles.
What counts as success is easily mistaken for spending less. An institution that cut its inference bill by routing every workload to the cheapest model and letting its controls lapse would have lower costs and worse economics: spend it still could not attribute, on outputs it could no longer defend. Success is inference spend that someone owns and can account for. Lower spend may follow, but it is a result, not the objective.
The published rate answers a narrow question: what the provider charges. It does not answer the one that matters, which is what the institution will spend to run the model defensibly, at its own utilization, under its own controls, charged to the unit that consumes it. Organizations that take up that harder question now will set their AI economics deliberately. Those that wait will adopt a structure built around someone else's assumptions, and learn its terms only when the spending has grown too large to ignore.
The parallel to cloud holds at the level that counts. Cloud created its cost discipline to solve spend that no one owned. Intelligence economics exists to solve a harder version of the same problem: outputs, and the decisions built on them, that no one has been made accountable for. The institutions that won cloud economics built the discipline before they were forced to. The same window is open now, and the same advantage goes to whoever treats intelligence as a managed input before its cost becomes an institutional liability rather than a line item.